What is web crawling and how can we optimise for it?

Emil Wallgren
Senior SEO Solutions Engineer
Crawling is fundamental for organic search engine visibility. In fact, it’s the first factor that websites must allow to be able to show up in organic search results at all. Learn what crawling is, why Google crawls and how we can optimise for it!
What happens when you search?
When you search in a search engine such as Google, what gets returned in the organic (non-paid) search results are the best matching pages from Google’s index. What this means is that you’re not actually searching the web, you’re searching through Google’s index of the web.
If we imagine a page on your website as an example. If people search for a search term related to your page, Google must first have found your page, stored it in its index, and analysed it to assign relevance for possible search queries it could be relevant for. Then your stored page gets served from the index into the search results when Google deems it appropriate to do so (based on a lot of different ranking factors).
There are hence 3 processes that must happen before your page actually shows up in the search results:
- CRAWLING
Finding the page (to know that it exists) and also constantly revisiting the page to see if it has updated in any way. - INDEXING
Analysing the page to find out what it is about and what kind of queries it can be associated with. It here also gets stored in the index together with all of the info that the analysis has concluded. - SERVING
Based on the ranking algorithm, your page can get picked and assigned a position in the search results based upon how relevant Google deem your page to be to the typed search query.
It’s first now that we can see your page in the search results.
This is a good video that describes the entire process as well as how crawling fits into that process:
How does a crawler work?
Now we know that the purpose of a web crawler is to discover new documents on the web and also to revisit them to see that they’re still working, if they still exist or if they have updated the content. Think of a web crawler as a way to scan the web to see how it looks and how it’s connected. Basically as a way to provide fresh insights around the structure of the web.
In the following documentation, we will outline how Google’s crawler works. The name of Google’s crawler is called GoogleBot.
GoogleBot and Crawling
Now we know the purpose of a web crawler, but how does the technical process of crawling works?
Let’s start with how Google first finds out that your website exists
Let’s say that Google won’t even know that your website exists. The 2 most common ways for Google to find out that your website exists are:
Submitting it to Google Search Console:
If you submit your website to Google Search Console, Google will at least have one URL (often the home page) it can use as a starting point for crawling the rest of your website.
Reaching your website from other websites linking to you:
If your website is unknown to Google, it can find it if other websites (which Google knows exist) link to you. Google will then follow these links and find your website.
How does Google find the rest of your website?
Now that Google has found at least one page on your website, there is a process for how it finds the rest of your pages. It simply works like this:
- Google looks into your source code
- It then finds and extracts all of the internal links on your page
- The new links to other pages on your website (URLs) are put into a crawl queue
- GoogleBot visits the links (URLs) in the crawl queue individually
- The process repeats itself for every internal URL it finds until Google has found all of the pages on your website
The second alternative to help Google find pages
Google has stated that sitemaps are the second biggest aspect for discoverability of web pages. A sitemap is simply an XML-feed that you can submit to Google as an alternative way to find the URLs of your website. It does not replace internal crawling as described above but helps Google easier find URLs that otherwise could take some time to discover.
Crawling of JavaScript rendered applications
A guide around crawling wouldn’t be complete without covering the crawling of JavaScript rendered applications. Many of these applications require JavaScript to render the content of their pages, including internal links.
The problem with that is that it is very resource-heavy to execute JavaScript rendering. Even though if Google has great resources, rendering JavaScript-heavy applications all of the time over the entire web is even too heavy for Google. Hence these URLs are put into a render queue, then rendered, and first after that Google can extract internal links (if internal links are rendered through JavaScript). Your pages could be in the render queue for many weeks before rendering takes place. This means that crawling becomes very slow and the discoverability of URLs on your website can take a long time.
A solution for this is a topic called dynamic rendering. Something we will cover more in the upcoming chapter “How to optimise for crawling”.
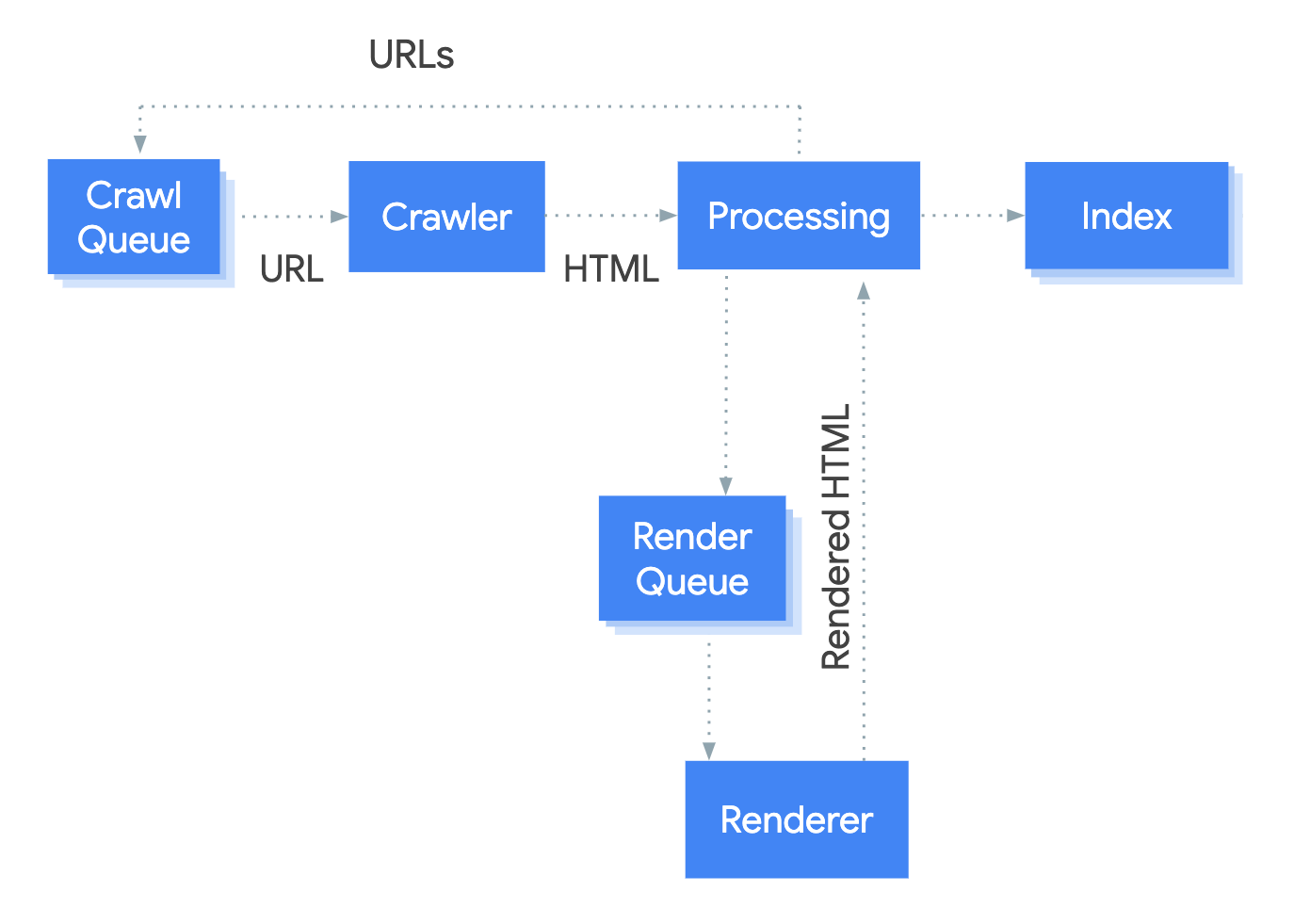
Image from developers.google.com
Crawl Budget
Does Google crawl your entire website in one go, every day? The answer is no. There is something called a crawl budget and it is exactly what it sounds like. You have a specific budget in terms of the span of a number of URLs that Google allocates to crawl your website every day. The reason is that Google doesn’t have enough resources for this and that Google doesn’t want to overload your servers with requests every day (which could slow down and affect user experience for your actual users).
A way to measure how many URLs Google crawl/day is to go into your Google Search Console account, click on the Crawl Stats report. This graph shows you the amount of URLs that have been crawled every day for the last 90 days. As you might see, it can differ greatly from day to day but you should at least get a basic idea regarding what span of the number of URLs that your crawl budget contains.
How to optimise for crawling
When it comes to optimising for crawling, there are mainly two focus areas to look deeper into:
- Focus crawling towards strategic pages to get these crawled more often. When you update content on your pages, this will increase the probability of changes quicker getting into the index.
- Raising the overall crawl budget of your website so that more pages get crawled per day.
There are many ways to optimise for crawling. But the following subchapters breaks down some of the biggest aspects that you can control.
Robots.txt
Robots.txt is a file located at the root of the website. The main purpose of this file is to provide rules for GoogleBot regarding what URLs not to crawl. By implementing rules in this file, you can steer where Google should focus its crawling. Google looks into this file before it starts to crawl your website. This is hence a quick win if you have a lot of URLs you consider unnecessary to focus crawling on. Great examples of URLs to disallow crawling from here could be pages containing filter-parameters that you don’t want to index. This means that Google should be able to crawl more static pages that you want to index in your crawl budget.
Dynamic Rendering
We have previously discussed the possible problems with crawling related to JavaScript-rendered applications. A solution to this is to implement dynamic rendering. Dynamic rendering can be technically challenging to implement (depending upon how your platform is set up), but the underlying concept is easy.
The concept is that you show your regular application to users, but a pre-rendered application to GoogleBot (and other important bots). Pre-rendering means that you already have assembled the documents as they will look in their final version (when JavaScript has executed), and you then show that premade version for GoogleBot so that Google doesn’t have to do the heavy lifting in terms of rendering the documents. This could speed up crawling heavily since you don’t have to wait for Google to render the documents before it can read the documents completely or follow internal links.
Here is a good video explaining this in a more simple format:
Sitemap Structure
Since Google prioritises URLs in sitemaps for crawling, you can submit URLs here that you want to crawl more frequently, but also new URLs to get them crawled faster than the process where Google has to follow internal links to reach them. Keep in mind to be as strategic as possible when selecting URLs for inclusion in your sitemaps. If you have a very large web-application with millions of URLs, and a crawl budget of 300 000 URLs/day, it’s not going to make sense to include all of your URLs in your sitemaps since this doesn’t really prioritise crawling to a specific sample. A good sample to include in your sitemaps are URLs with content that updates frequently and new URLs. This will keep your application or content more up to date in Google’s index as well as indexing of new URLs can go faster.
Page Speed & Server Performance
GoogleBot does not want to overload your servers while crawling. If it feels that the response-time from your server is getting slower and slower, it will back off from crawling and continue at another time. If you then optimise your pages to quickly serve content to GoogleBot and your servers to handle heavier requests from Google, GoogleBot will crawl more aggressively which for you means more crawled URLs / time that GoogleBot visits your web application. In short, optimising page speed increases the overall crawl-budget.


