Building a modern marketing data warehouse

Anton Tikjøb Hagedorn
Lead Data Strategist
This is the second post on our series looking at why your main marketing goal should not be building a unified customer journey. The aim of this post is to give some answers to the obvious question: If we’re not looking to build a unified customer journey, what is the plan?
We have chosen to divide the solution into three different approaches, all related to creating a customer or marketing data warehouse and activation hub. We’ll go deeper into each of the areas, but to begin with, here is a quick overview:
The three approaches to data warehouses
1. The cookie-less marketing data warehouse
What is possible with this approach? To get the optimal top-level and per channel budget allocation; understand what each channel or campaign is worth.
What is not possible with this approach? Evaluate marketing performance based on path based; data driven attribution methods or through incrementality (lift) studies; audience segmentation/activation; CLV calculations; improved bidding signals.
Data needed: Aggregated marketing performance and cost data (daily) and aggregated sales data (no cookie, user, or customer IDs)
Activation possibilities: Cross channel marketing performance reporting; cross channel budget allocation; intra channel (across campaigns) budget allocation.
2. The customised data-driven attribution warehouse and activation hub
What is possible with this approach? Understand what each channel or campaign is worth based on data driven attribution methods; ability to set the correct target in the channels (and per campaign); apply data driven attribution bidding.
What is not possible with this approach? Audience segmentation/activation; CLV calculations; marketing mix modeling; cookieless marketing evaluation.
Data needed: Purchase channel paths (cookie and/or user-based).
Activation possibilities: Cross channel performance reporting; target setting; bidding.
3. The modern customer data warehouse
What is possible with this approach? Supply the bidding algorithms with better conversion signals (smarter bidding); apply smarter targeting and communications in digital marketing channels; CLV calculations; clustering, and more.
What is not possible with this approach? Evaluate marketing performance.
Data needed: Cross channel (web, CRM etc) cookie and customer data.
Activation possibilities: Better bidding signals; audiences; segments adapted for each output channel.
Of course, it’s possible to target all the above approaches, as each of them fills a unique purpose. However, we recommend starting with one of them. Otherwise, there’s a risk of getting stuck in the data collection phase and remember that 80% fail in the activation phase.
How do I know what suits my company?
Our experience tells us that to succeed with these types of projects it’s crucial to place as much focus on the organisational aspects as on the technical ones. This includes everything from getting internal buy-in, to keeping momentum during the implementation phase and clarifying ownership and responsibilities.
It’s important to define which disciplines should be handled by an external party (consultants, SaaS platforms, etc) and what disciplines need to be handled by internal stakeholders. You should clearly define the competencies that are required in-house. This is our recommended process to define the optimal approach (1,2 or 3), taking into consideration the organisational aspects:
Each of the three approaches could be divided into four disciplines (data collection, data stitching/cleaning, analysis/segmentation, and activation).
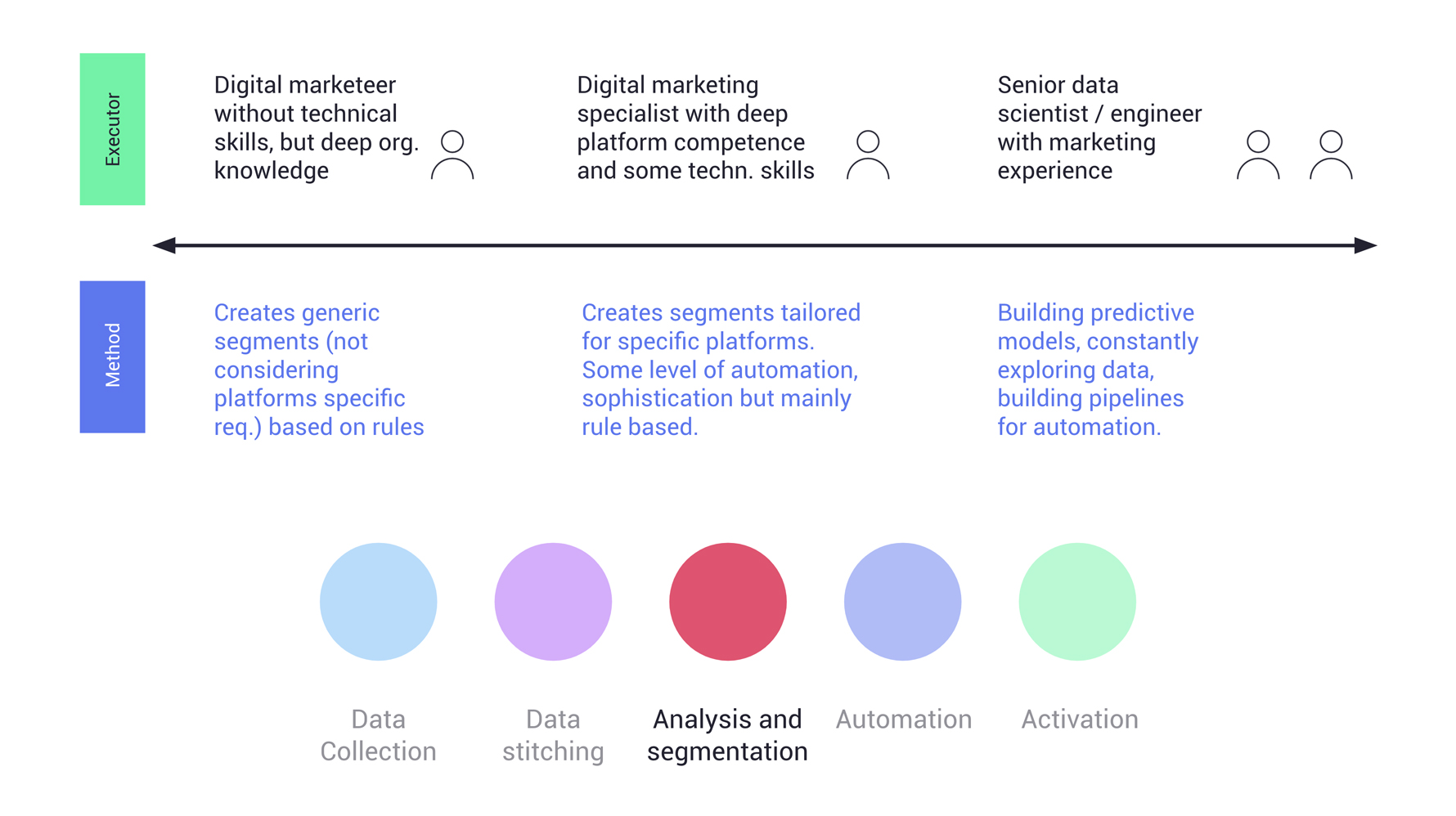
Map each of the four disciplines (e.g. analysis/segmentation) and define the most suitable decision makers and owners for implementation, taking into account the level of sophistication required (for example rule based vs predictive modeling).
Method for junior digital marketers
In the example below, on the left we see that if the implementation owner were to be a digital marketer without deep technical knowledge, the most suitable method for segmentation is most likely to be rule-based audiences built through a user interface.
Method for more experienced digital marketers
In the example to the far right, we see that if the preferred implementation owner were to be a data engineer or scientist, the method can be more advanced. In this scenario the digital marketeer could be the decision maker but not the implementation owner. We should start by deciding on the preferred method and let that decision guide the selection of implementation owners.
Example: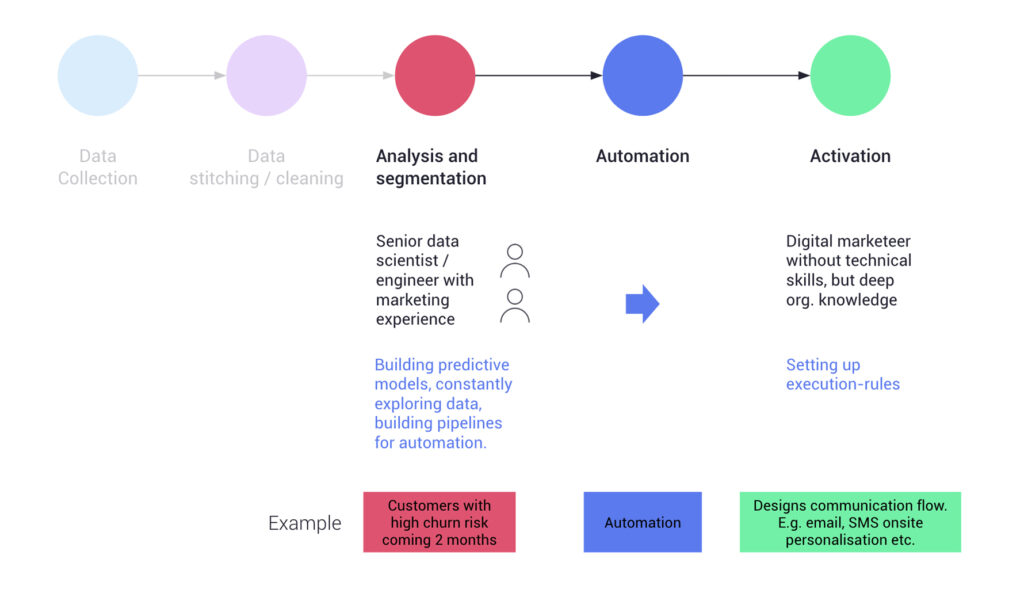
Based on the above requirements, continue the mapping exercise by defining the most suitable approach for each discipline.
Method for advanced digital marketers
In the example below, the desired level of sophistication for the analysis/segmentation phase is ‘advanced’ (predictive modelling), hence a user interface is not needed (guiding the choice of technology). In contrast, for the activation phase, manual execution needs to be set up (and frequently often modified), hence the requirement for a user interface.
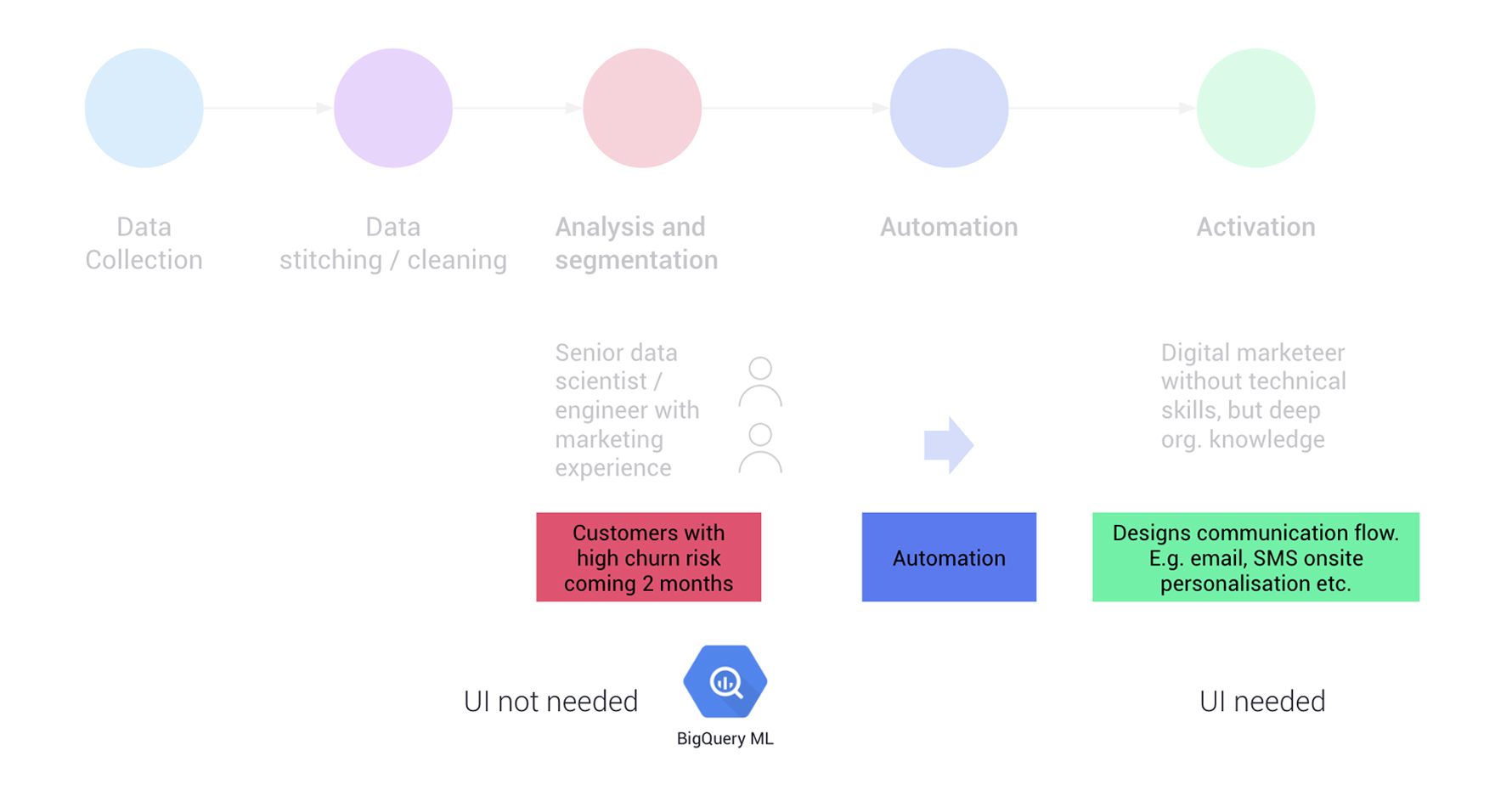
What next?
To sum up, we recommend considering what points on the automation scale (from 100% manual to 100% automated) and the sophistication scale (from 100% rule bases decided by a human to 100% algorithmically-based) you see as being the sweet spot for your business. This should guide competency planning and in-house vs. consultancy needs.
Our hope is that our blog post series will take you one step further in finding the most suitable approach as well as the ideal method for the chosen approach, taking organisation considerations into account.
This is part of a 5 part series on attribution. Apart from technical planning, there is another critical aspect to have in mind from the start – privacy. The third post in the series will cover this topic.
- Part 1: Why your main goal should not be to build a unified customer journey
- Part 3: Setting a first-class privacy strategy
- Part 4: Capture, store and activate the right data
- Part 5: Attribution 2.0
In more detail
If the article above has got you itching for more info we’ve put together our recommendations on what solutions to go for when it comes to building your data warehouse. We’ve done the research so you don’t have to!
Cloud vs On-premise
Before looking into our recommendations on how to build each of the three marketing/customer data warehouses, we will briefly stop to consider whether our technology should be Cloud-based or on-premise. Our opinion is that this is not a choice you should spend too much time on since we believe a Cloud-based approach is the only way to go. We have listed the most important arguments (which you could bring to your CTO) here:
- Scalability – Easily scale infrastructure up and down (to zero) which can yield significant cost savings vs fixed cost architecture (e.g. Google Cloud Functions, Google Cloud Run, Cloud Dataflow).
- Reduce DevOps/Infrastructure Burden – The proliferation of Managed Services in Cloud Environments allows users to readily deploy business logic without worrying about provisioning and maintaining infrastructure (e.g. Google App Engine, Google Kubernetes Engine).
- Availability of Global Scale Products On Demand – Ready access to the “backbone” systems that some of the largest companies in the world use to manage their services, allowing for “unlimited” scalability (e.g. Pub/Sub, BigQuery, Cloud Storage, BigTable, Global Load Balancer).
- Secure Access To All Resources from the Browser – You can easily track all resource deployments from a single “pane” and manage IAM/RBAC policies as well as “hardware” from a single place (IAM, IAP, GCP Monitoring, Cloud Logging, gcloud CLI, GCP Web Application).
What Cloud provider to consider?
Our preference is the Google Cloud Platform. Like other cloud providers, Google Cloud Platform offers a comprehensive portfolio of Compute services (e.g. VMs, Managed Kubernetes, Managed Database, etc), but its primary differentiator is in the focus around data at scale. Solutions like BigQuery, Pub/Sub, and DataFlow provide highly scalable serverless methods for the storage, transmission and management of large volumes of streaming/batch data. BigQuery ML, AI Platform, DataStudio and DataProc (managed Hadoop/Spark) provide seamless integrations between data and modelling resources to gain insights.
In addition, Google Cloud Platform has many integrations with the Google marketing products, making the ingestion and actionability of marketing data more efficient. Good examples include Google Marketing Platform connectors to GCP (e.g. Google Analytics 360, Data Transfer for Google Ads, etc) and the upcoming Ads Data Hub product.
The most important considerations when building your data warehouse
To make this blog post as useful as possible we have listed our views on the most important considerations/choices for each approach.
1. The cookieless marketing data warehouse
The SaaS black box vs. a custom setup
The first decision is whether a custom setup suits you better than a software license, or vice versa. Let’s recap the software available. The really strong options include OptiMine and Aiden. A major benefit of choosing existing SaaS platforms is the relatively short time needed to get a functioning tool up and running. A wide range of connectors are available and the models are quite advanced.
However, keep in mind that many of these solutions are a bit of a black box. This goes not only for the models themselves but also the fact that your data is collected in someone else’s Cloud. In most cases, you only have access to the output itself (eg. in a user interface) and not the underlying data and models. This means it’s much harder to re-use the raw data for other purposes. The potential for customisation can also be limited. Finally, don’t expect to only pay for the license itself; in many cases, you’ll need consultants for implementation or ongoing services.
The benefits of a custom setup are more control over the data and the model, and a far larger potential for customisations. Unless you have a really strong in-house team you will most likely pay more for consultants, but less for licenses.
Fetching data
If you go for a custom solution you need to make a few important decisions when it comes to data fetching. Generally speaking, there are three different ways to go. You can build your own connectors, buy a license for a third-party tool (such as Supermetrics or Funnel.io), or rely on connectors built by someone else (for example your agency).
Let’s walk through each option:
- Develop own connectors – The most time-consuming option, but also most flexible, allowing for maximal customisation. In the long run, this could be the cheapest alternative, especially if you have developers in-house. Think about the overall number of connectors you need to build and how you will handle the ongoing maintenance as APIs get updated across all the platforms you integrate with.
- Funnel.io – If your purpose for Funnel.io is mostly the connectors, it’s an expensive solution. Funnel’s strengths lie in its data blending capabilities, though it’s important to note that the blending happens behind the scenes. The output is accessible in many different formats (for example, pushed to a BigQuery-project), but you lose insights into how the data is joined and it can’t be re-used for other purposes such as audience segmentation or activation. The data isn’t provided at a granular enough level.
- Supermetrics – Similar to Funnel.io, but more cost-effective as it doesn’t offer the blending possibilities. If the main purpose is to pull data and do the blending yourself it could definitely be a good starting point or a complement to connectors that you build yourself.
- Rely on connectors built by someone else (for example, your agency) – The key questions to consider here are where the data is stored, how much access you have to it, what SLAs are in place, and what the total long term cost is going to be.
What model to choose?
The final, but perhaps the most important decision, is what model to use/build and how to activate the insights. More about this in blog post 5 in this series.
2. The customised data-driven attribution warehouse and activation hub
There are a few acceptable out-of-the-box attribution software solutions out there, but given the significantly increased need for customisation (due to privacy regulations and trends), we’d recommend that you don’t completely rely on an out-of-the-box solution.
Instead, you should build your own solution (or have someone else help you build one) using a mixture of your own solutions and existing ones. Be aware that path based attribution has its challenges; no matter how much effort you put in, your solution won’t perfectly reflect the truth – but that said, the foundation for all the big performance advertising platforms is the conversion signals. The competitive advantage of providing the bidding algorithms with the smartest signals possible will be even bigger going forward.
What data source/collection method to rely on?
The underlying data (paths) is absolutely crucial. You should spend as much time as possible getting it right. There are a few different possibilities available when fetching the data/paths, and we’ve listed the most common ones here.
- Google Analytics 360 – Comes with native integration to BigQuery, which is a huge benefit. It’s important to bear in mind that the path data (which you can find in the Multi-Channel funnel reports) are not available in the BQ export. This means you will need to create your own paths, based on the raw export. This opens up lots of possibilities for customisation but also requires some work and automation.
- Google Analytics (standard) – To access the raw data you need to use the Reporting API. This has drawbacks. Just to reach a point where you have all raw data available (for example in a BigQuery table) is a rather complex task. You might run into sampling limitations or other limitations with getting all of the dimensions and quantity of data that you need.
- Google Analytics Web + App property – The standard version comes with a native BigQuery integration, which is promising for advertisers without the budgets for Analytics 360. However, the product is still in development and there are a few important limitations in building robust datasets for data-driven attribution. The roadmap is developing quickly so watch this space!
- Google Analytics Multi-Channel Funnel reports – One straightforward approach is to use the Multi-Channel Funnel API. By doing this you don’t need to invest time building the paths yourself. However, opportunities for customisation are more limited. In addition, only converting paths (not non-converting paths) are available; a major drawback.
- Facebook attribution – Not currently a viable option given the fact it’s not possible to automate the export of conversion paths, but if Facebook offers that possibility in the future, this could be extremely interesting. A deep dive on Facebook attribution can be found here.
- Own tracking solution – Very time consuming so not often a viable option. Offers a lot of flexibility.
3. The modern customer data warehouse
This is definitely the area where the most software exists and fights for attention. Personalisation tools, marketing automation software, customer data hubs – the names are varied but the capabilities do not differ much.
SaaS and a user interface vs. custom solutions
This decision is related to organisational considerations. Generally speaking, a custom solution offers more sophisticated machine learning possibilities (e.g. Google Cloud Platform offers BigQuery ML as well as AutoML, to mention a few). If the custom data platform has machine learning capabilities, they can be hard to customise, but it’s often a must to make them suit your business. Custom solutions offer more possibilities when it comes to data stitching.
We strongly recommend striving for as much control and customisation potential as possible when it comes to data stitching and analysis (the “engine”).
For the activation piece, a user interface is often needed. We believe this is the biggest requirement in a marketing automation platform. In most cases, a human needs to be in control of the actual orchestration, especially when it comes to 1-2-1 communication (email, SMS, push notifications, etc). However, the logic/segments should be fed from the modern customer data warehouse. There are some advantages to having everything in one out-of-the-box platform (collection, stitching, logic, orchestration) but this comes with several limitations that we should be aware of.
Segments vs. Signals
When building a modern customer data warehouse, our recommendation is to make bidding signals equally important as audience segments when feeding data to the channels. Often bidding signals are forgotten, and the focus for data sharing to the channels relies too heavily on audiences. Also, it’s common that all output channels are treated in the same way.
An example is the Customer Lifetime Value models. Having some kind of CLV signals in place is important for most businesses, though the outcome doesn’t always have to be the sharing of customer value segments with the channels. In many cases, sending enhanced conversion signals to the platform based on the future expected value of a user can have a positive impact on bidding efficiency and the acquisition of high-value customers.


